| Zurück | Weiter |
Funktionieren die bisher beschriebenen Tests auch mit Inhalten, die nicht ISO-8859-1 sind, beispielsweise mit russischen, griechischen oder chinesischen Texten und Metadaten?
Eine schwierige Frage. Denn auch wenn bei der Entwicklung von PDFUnit viel Wert darauf gelegt wurde, generell mit Unicode zu funktionieren, kann eine pauschale Antwort nur gegeben werden, wenn die eigenen Tests für PDFUnit selber mit „allen“ Möglichkeiten durchgetestet wurde. PDFUnit hat zwar etliche Tests für griechische, russische und chinesische Dokumente, aber es fehlen noch Tests mit hebräischen und japanischen PDF-Dokumenten. Insofern kann die eingangs gestellte Frage nicht abschließend beantwortet werden.
Prinzipiell tun Sie gut daran, sämtliche Werkzeuge auf UTF-8 zu konfigurieren, wenn Sie Unicode-Daten verarbeiten müssen.
Die folgenden Tipps im Umgang mit UTF-8 Dateien lösen nicht nur Probleme im Zusammenhang mit PDFUnit. Sie sind sicher auch in anderen Situationen hilfreich.
Metadaten und Schlüsselwörter können Unicode-Zeichen enthalten.
Wenn Ihre Entwicklungsumgebung die fremden Fonts nicht unterstützt, können
Sie ein Unicode-Zeichen in Perl mit \x{nnnn} innerhalb eines
Double-Quoted-String schreiben, wie
hier das Copyright-Zeichen „©“ als \x{00A9}:
# # The document info 'producer' contains the copyright as a Unicode charactere. # lives_ok { my $pdfUnderTest = "$resources_dir/unicode/unicode_producer.pdf"; AssertThat->document($pdfUnderTest) ->hasProducer() ->equalsTo("txt2pdf v7.3 \x{00A9} SANFACE Software 2004") # 'copyright' ; } "value of producer contains Unicode";
Selbstverständlich können Sie im Perl-Code direkt Unicode verwenden.
Dann dürfen Sie aber nicht die use utf8; Anweisung vergessen.
Das Test mit Unicode sieht dann so aus:
# # The document info 'subject' contains Unicode. # lives_ok { my $pdfUnderTest = "$resources_dir/unicode/unicode_subject.pdf"; my $expectedSubject = "Εργαστήριο Μηχανικής ΙΙ ΤΕΙ ΠΕΙΡΑΙΑ / Μηχανολόγοι"; AssertThat->document($pdfUnderTest) ->hasSubject() ->equalsTo($expectedSubject) ; } "test subject with Greek characters";
Wenn Sie XML-Dateien in Eclipse erstellen, ist es nicht unbedingt nötig, Eclipse auf UTF-8 einzurichten, denn XML-Dateien sind auf UTF-8 voreingestellt. Für andere Dateitypen ist aber die Codepage des Betriebssystems voreingestellt. Sie sollten daher, wenn Sie mit Unicode-Daten arbeiten, das Default-Encoding für den gesamten Workspace auf UTF-8 einstellen:
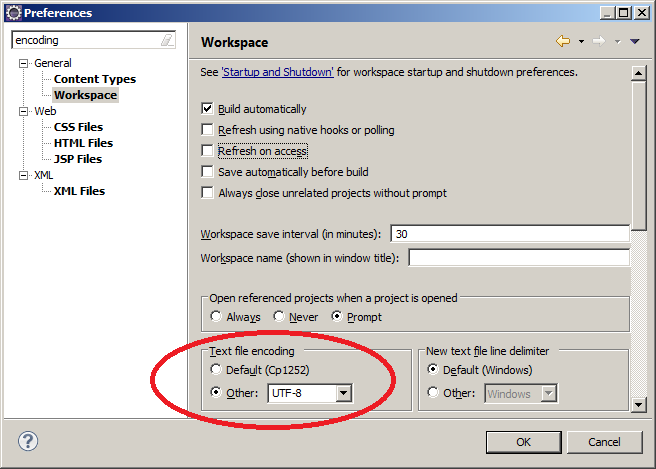
Abweichend von dieser Standardeinstellung können einzelne Dateien in einem anderen Encoding gepeichert werden.
Im praktischen Betrieb trat einmal ein Problem auf, bei dem ein „non-breaking space“ in den Testdaten enthalten war, das zunächst als normales Leerzeichen wahrgenommen wurde. Der String-Vergleich lieferte aber einen Fehler, der erst durch die Verwendung von Unicode beseitigt werden konnte:
# # String ends with NBSP. # lives_ok { my $pdfUnderTest = "$resources_dir/unicode/xfaBasicToggle.pdf"; my $defaultNS = DefaultNamespace->new("http://www.w3.org/1999/xhtml"); my $nodeValue = "The code for creating the toggle behavior involves switching " . "the border between raised and lowered, and maintaining the button's"; my $nodeValueWithNBSP = $nodeValue . "\x{00A0}"; # The content terminates with a NBSP. my $nodeP7 = XMLNode->new("default:p[7]", $nodeValueWithNBSP, $defaultNS); AssertThat->document($pdfUnderTest) ->hasXFAData() ->withNode($nodeP7) ; } "check for invisible blank (nbsp)";